Atlas da busca
Fichamento do texto "Mapa da busca"1 de Rodrigo Ochigame e Katherine Ye.
Abstract
The internet is full of invisible borders—geographic, linguistic, cultural, political—that circumscribe the information each user sees. Search engines shape such “information borders” by tailoring results according to geolocation, language, and other user profiling. We present Search Atlas, a tool paired with visualizations that enable users to see and cross these borders. For instance, how do search results for the same query differ for Brazilian, Turkish, and Indian users? Given a query, the tool displays multiple lists of Google search results, highlighting distinctive words for each set of parameters. Then, we provide visualizations that juxtapose and cluster Google results across countries, revealing new information borders and regions that can vary widely depending on the query. By exposing the partial perspective of a search engine, Search Atlas invites users to experience the internet from divergent positions and to reflect on how their online lives are conditioned by technological infrastructures and geopolitical regimes.
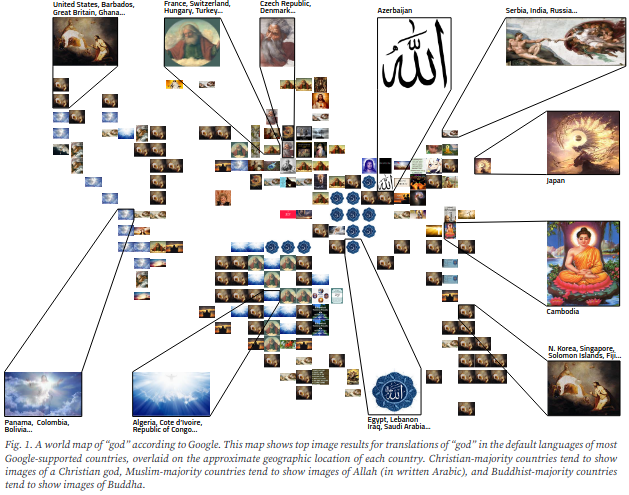
, and Buddhist-majority countries tend to show images of Buddha.")
Hipótese: buscador Google como modulação
How many times did you Google something today? Think of all the search results you have seen over the years, and how those results have gradually shaped your opinions, behaviors, identities, worries, and hopes; your ideology, your friend circle, and your worldview. (p. 1971)
Google como um deus onisciente benevolente
Trusting Google is understandable. Google tries to create the impression of a benevolent, all-seeing god. It claims that its search algorithms “sort through hundreds of billions of webpages” in an index that “contains more info than in all the world’s libraries put together” in order to “find the most relevant, useful results for what you’re looking for” [1]. This impression is only reinforced by the minimal design of Google’s search engine interface, which omits its “partial perspective” [2], that is, the combination of choices that inevitably exclude some points of view in favor of others. Fig. 2 illustrates some of the invisible processes that shape the production of search results. (p. 1971)

Política dos mecanismos de busca
Search engine design is not just a technical matter, but a political one. Designers make consequential political choices regarding which sites to include and which to exclude, how to rank the included sites, and how to determine a site’s “relevance” for a given query. For more than two decades, an expansive body of research has queried the politics of search engines. Even the earliest studies, based on anecdotal observations, already suggested that search engines systematically suppress some sites in favor of others, in line with financial interests [3]. More recent studies have argued that commercial search engines deploy algorithms that reinforce existing social structures, particularly racist and sexist patterns of exposure, invisibility, and marginalization [4]. Thus, it is vital to expose the partial perspective of search engines. (p. 1971)
Problema: código fechado dificulta a obtenção de dados empíricos
Yet, researchers face a recurring challenge: since the algorithms of commercial search engines are proprietary and secret, it is difficult to gather empirical evidence about their social effects [5, 6, 7]. (p. 1971)
An even greater challenge is to study how search results for the same query differ for different users. Many search engines tailor results according to geolocation, language, and other user profiling. In this sense, the internet is full of “information borders” that users cannot easily cross. And despite an abundance of public discourse about “echo chambers” and “filter bubbles” on the internet [10, 11], the available evidence on the precise scope and magnitude of those borders remains ambivalent [12, 13]. It is still unclear how search results differ across geographic, linguistic, cultural, political, and other borders [14]. (p. 1971)
Proposta: estudar seus resultados
But even in the absence of access to proprietary algorithms, it is possible to study their outputs: search results. (p. 1971)
Atlas como coleção de mapas (de conhecimento), Search Atlas como exame das bordas informacionais
Our project, Search Atlas, offers a critical examination of these information borders. Starting in the late sixteenth century, an “atlas” has meant a collection of maps. Despite their aspirations to surveying the entire world and providing definitive accounts of its geopolitical territories, atlases have always been shaped by the assumptions and interests of their makers. Today’s digital maps are no different. For disputed territories, Google Maps shows different maps depending on the location of the viewer. For example, if you view Google Maps from India, the region of Kashmir appears to be part of India, shown with a solid border. But if you view Google Maps from anywhere else in the world, a dotted border near Pakistan makes it clear that Kashmir’s ownership is disputed [15]. (p. 1972)
By the mid-nineteenth century, the term “atlas” had spread from geography to the empirical sciences more broadly, ranging from astronomy to botany to anatomy. Atlases became not just collections of maps in the traditional cartographic sense, but “maps” of knowledge in a general sense [16]. If today’s search engines are the most extensive and systematic maps of knowledge available, Search Atlas offers a way to compile and compare these maps. But unlike most atlases, Search Atlas does not aim to present an all-encompassing, objective view of the world. Following critical cartographers [17], we appropriate the concept of “atlas” to show that search results are always partial and contested. (p. 1972)
Partes do projeto Search Atlas
- A tool that enables users to search for any query in any three Google-supported countries (with accompanying languages), returning Google’s text and image results for each set of parameters. Users may optionally have their queries machine-translated into each language and the results translated back into their own language. Then, the tool highlights the most distinctive words in each list of results. Example queries are shown in Figs. 3, 4, 5, and 6.
- A collection of image maps (Figs. 1 and 7) that show the image results for selected queries in almost every Google-supported country. The top images are placed on a tile map in the approximate geographic location of the result’s country of origin.
- A collection of cluster maps (Figs. 8 and 9) that reveal “information regions” and “information borders” in text results for selected queries worldwide. Queries are performed in the Google-determined default language for each country. Then, the results are machine-translated into English, and automatically clustered by text similarity, so countries with similar results are spatially grouped together.
Outros trabalhos de arte relacionados
Media art offers precedents for designs that defamiliarize an individual user’s experience with a technology in order to make a point about their everyday experience. For example, Taryn Simon and Aaron Swartz’s “Image Atlas” (2012) juxtaposes image search results for a single query in multiple search engines in different countries, arranging the results into a list of hundreds of images. Simon and Swartz presented their project as a study of “cultural differences and similarities’’ across the world and as an investigation of mediation: how “tools like Facebook and Google ... are programmed and are programming us” [20]. Recent media interventions have continued to explore ways to transgress the algorithmic filters imposed by online platforms. “PolitEcho” (2017) visualizes the “filter bubble” of one’s Facebook friends [21], and Mozilla’s “TheirTube” (2020) simulates YouTube video recommendations for users with different cultural profiles, such as “liberal” or “conservative” in the U.S. sense [22]. By juxtaposing divergent views, our interface follows these tactics for making users aware of the layers of mediation behind the information they receive (p. 1972)
SearchAtlas como ferramenta de uso contínuo: modulação pela usuária
However, we present Search Atlas not just as an art piece that facilitates a one-time experience, but as a tool that could be plausibly used in everyday life. Thus, Search Atlas can be understood as a work of critical design [23, 24, 25]. For example, mainstream search interfaces like Google’s make the design assumption of a single language and a single location per user. Our interface questions the value judgments of this “affirmative design” [26] by supporting user personas that are underserved, such as those of migrant and multilingual populations. By encoding values of cultural and linguistic multiplicity, Search Atlas invites users to speculate on the kind of world that would surround it (à la [27]), a world where interfaces that embrace plurality are not the exception but the norm (p. 1972-3)
Engenharia crítica
Yet our work also seeks to move behind the interface, to probe the technical operations of search algorithms. As the Critical Engineering Manifesto puts it, “The greater the dependence on a technology the greater the need to study and expose its inner workings” [28]. Could internet users be any more dependent on search engines? Putting this manifesto into action, the Critical Engineering Working Group produces custom software that exposes the inner workings of widespread but ill-understood technologies. While, in our setting, it is not possible to “open the black box” of proprietary search engines as one can open a cell phone, we study the workings of search engines scientifically, prodding them with exhaustive combinations of inputs and identifying patterns in their outputs. (p. 1973)
"Estudar para cima"
Overall, our work aims to “study up”: to appropriate the tools of the powerful, which are typically deployed against more vulnerable groups, to instead hold the powerful to account. This tactical move from anthropology is increasingly making its way into computer science as a reaction to the latter’s tendency to “study down” [29]. One example of “studying up” computationally is the Dark Inquiry collective’s “White Collar Crime Risk Zones” (2017) [30]. Rather than predict “blue-collar” crime as is typical with algorithmic risk assessment, this project uses machine learning to predict where financial, “white-collar” crime is likely to happen and visualizes the results. In what follows, we “study up” by applying standard data analysis techniques employed by search engines (like tf-idf [31]), as well as cutting-edge visualization techniques (like UMAP [32]) to search engine results. Our goal is to open up the search engine to critical interrogation. (p. 1973)
Amostra de resultados
In the following sections, we provide results for sample queries that reveal provocative differences between locations and languages. These differences are surfaced in our interface, which highlights the most distinctive words in the results for each location/language pair. The more often a word appears in each list of results (designated “red,” “green,” and “blue”), the stronger its color as a mixture of red, green, and blue. For example, a word that occurs only in the “red” list of results will be bright red, whereas a word that occurs equally in the “red” and “blue” lists will be purple. Words that are too commonly used in the language (stopwords) or appear too infrequently in the results are not highlighted. (Although this interface relies on color vision, we are working on more accessible interfaces that do not.) (p. 1973)




To create these visualizations {abaixo}, we machine-translate each query into the default language for each country using Google Translate. To determine the default languages, we scrape the google.com homepage with each possible country parameter (gl) and detect the language parameter (hl) set as default for each. (p. 1978)

Tendência do Google em utilizar língua colonial (versus nativa)
It is important to note that Google tends to select state-sanctioned and colonial languages as the default for a country. The default language for Mali is French, which is the state’s official language, even though Bambara s much more widely spoken. English is the default language for Pakistan even though Urdu is also official and others, such as Punjabi, are more widely spoken (p. 1978)
Regiões e bordas informacionais
Looking at the image maps, we readily notice ways to group countries. For example, when it comes to “god,” countries as far apart as Bhutan and Gibraltar lie in the same “information region”: searchers in both countries would find similar images of a Western god looking at a kneeling Jesus. On the other hand, countries as close as Egypt and Sudan lie in different information regions: searchers in Sudan would find the same Christian image, whereas searchers in Egypt would find a calligraphic representation of Allah. Regardless of the underlying causes, there is some kind of “information border” between these regions. (p. 1979)
Metodologia para mapear regiões informacionais
Specifically, we again make searches worldwide using the Google-determined default language for the country. Then, given the text results in that language, we machine-translate the results back into English, again using Google Translate. Each country’s English results can be understood as an approximately hundred-dimensional vector of its most distinctive words, found via the tf-idf algorithm [31]. (For example, Japan’s top words in its results for “god” are “japanese,” “shinto,” “kami” [spirits], and “awe.”) The similarity between two countries is quantified as the cosine similarity between their vectors. Finally, we use an algorithm called UMAP, which is state-of-the-art for dimensionality reduction [32], to arrange the countries in a two-dimensional space and automatically cluster them according to how similar their search results are. (p. 1979)
Note that each map we give is just one of many possible maps, since UMAP is a nondeterministic algorithm whose outputs depend on parameters related to the desired amount of global or local structure to visualize in the data. We choose parameters that lean toward preserving more global structure. Most importantly, the clusters in our analysis appear to persist throughout many runs of the algorithm. (p. 1979)
Regiões de informação

Several clear clusters emerge, which seem to be formed by a combination of common geographic location, language, and religion. Cluster 7 consists of Spanish-speaking Latin American countries, which also tend to be predominantly Christian. Top words include “universe,” “concept,” “representations.” Cluster 5 consists of Muslim-majority Middle Eastern countries. Top words include “throne,” “treasury,” “license,” “authorizing,” “transactions.” (p. 1979)
Francophone countries split into two separate clusters. Cluster 2 consists almost entirely of countries in the African continent, whether Muslim-majority or Christianmajority. Cluster 1 comprises France and its overseas territories and former colonies outside of Africa, ranging from the Caribbean Sea to the Atlantic Ocean to Polynesia. Yet there are exceptions: Haiti is in cluster 2 despite being a Caribbean country. (p. 1979)
Cluster 3 is intriguing because it is not easily legible through any of the lenses of geography, language, or religion. It includes countries as diverse as Macedonia, Turkmenistan, and Laos. While this cluster did not have a consistent set of shared top words, the UMAP algorithm judged them to be more similar to each other than to countries in other clusters. This automatically discovered cluster may comprise a new information region. (p. 1979)

The information borders of climate change seem to be defined largely along island versus continental lines. In cluster 3, comprising high-income countries in continental Europe, such as Germany, Liechtenstein, and Luxembourg, the top words suggested preemptive measures on “climate protection” (“protection,” “sensible”). Yet, the top words in a few island countries that form part of cluster 5, ranging from Mauritius in the Indian Ocean to Trinidad and Tobago in the Caribbean Sea, suggested much greater immediate threats (“vital,” “signs,” “harmful,” “vulnerability,” “enormity,” “daunting,” “dispiriting”). (p. 1980)
Some countries’ results tended to focus on governmental and institutional policy, while others emphasized individualistic action. The results of cluster 3 included sites of government organizations such as the German federal cabinet and the European Environment Agency. By contrast, the top words in the Netherlands, Aruba, and Suriname focused on consumer choices (“buy,” “consume”). In cluster 9, comprising mostly island countries, from Tonga to Sri Lanka, the top words suggested other household practices (“use,” “unplug,” “electronics,” “wall,” “socket,” “led,” “switch,” “lights”). In cluster 1, which includes some of the island countries most threatened by climate change, including Maldives and the Marshall Islands, the top words focused specifically on food choices (“daily,” “meat,” “avoiding,” “cows,” “farm,” “top,” “products,” “eat”). (p. 1980)
These findings are consistent with ethnographic studies of climate change discourses in the Marshall Islands, which have reported that “Despite awareness of their tiny carbon footprint, grassroots Marshall Islanders (if not their government) have strongly favored a response of guilt and atonement rather than outrage and protest” [36]. (p. 1980)
Dificuldades e limitações práticas
The implementation of our tool faced many obstacles. Google intentionally lacks an API for web search results, and deploys various tactics to block scrapers. Ironically, Google is a scraper itself, and profits massively off its scraping of sites. In fact, many sites block all crawlers except Google, due to bandwidth and other capacity constraints that could cause the sites to crash. This behavior creates a barrier to competition by alternative search engines. In the United States and in the European Union, antitrust regulators have cited this barrier among Google’s multiple measures to protect its monopoly power. Such measures also include contractual arrangements to make Google the default search engine in major web browsers and operating systems [37]. (p. 1981)
For researchers, the only legally safe and technically feasible way to obtain data of search results is to use a third-party scraper. We obtained data from an API operated by a third-party firm, which provides defense against Google’s legal threats and technical methods to block scrapers. Even then, our data collection has been costly, demanded a substantial amount of code, and faced several other obstacles. For instance, we could not obtain reliable search results from Myanmar. Although we could not determine the precise reason, one possible explanation was an ongoing military coup (at the time of writing) that involved a nationwide internet shutdown. We also could not include Botswana and Seychelles because Google Translate does not support their default languages, Setswana and Seychellois Creole respectively. (p. 1981)
How to interpret those new information regions and borders? The underlying infrastructure offers few answers. To return results, Google Search relies heavily on novel deep learning systems whose decisions are notoriously difficult to interpret, even by Google’s own researchers [38, 39]. Moreover, our results for information borders and regions are limited by the difficulty of comparing results across geopolitical borders. Our results may be influenced by confounding factors related to language, which are hard to account for in this kind of global investigation, or by mediating factors such as Google’s machine translation and the UMAP algorithm. (p. 1981)
Buscador como resultado de padrões culturais e desenhos específicos de algoritmo
To get feedback on how people receive our results, we shared early prototypes of Search Atlas in participatory workshops with computer scientists, artists, and designers. In these sessions, we noticed two common temptations in interpreting the results of the tool. One is to interpret the results as straightforward reflections of cultural differences among users in different countries. Another is to interpret the results as unambiguous outcomes of political bias or manipulation by algorithm designers. We encourage our readers to resist both of these temptations. Search engines are not entirely neutral conduits that respond to users’ interests with objectively “relevant” results, nor are they reducible to purely subjective editors with unlimited power to pick and choose [40]. Rather, our results underscore how search engines are products both of cultural patterns and of algorithm design choices. (p. 1981)
Search engines respond both to users’ immediate interests and to corporations’ financial imperatives. The design of Google’s search engine is inseparable from the priorities of its advertising business [41]. Search engines also respond to political pressures and legal regulations. China-based search engine Baidu favors results that align with the views of Chinese government authorities [42], and Google removes results to comply with European data protection laws [43]. (p. 1981)
Moreover, search results are products not only of algorithm design but also of human judgment and curatorial labor. Google employs subcontracted workers, such as “raters” who judge the perceived quality of search results and “content moderators” who judge whether results seem inappropriate or illicit [44, 45, 46]. The production of search results also involves other actors with competing interests and goals, such as “search engine optimization” (SEO) consultants who deploy various tactics to help their clients compete for attention [47]. (p. 1981)
Finally, designers in different places also have different cultural assumptions, concerns, and practices, all of which shape the design of their search engines. According to the co-founders of Yandex, now Russia’s most popular search engine, their initial demonstration product was an algorithm for searching a Russian version of the Bible, later adapted for searching the web [48]. (p. 1981)
-
OCHIGAME, Rodrigo; YE, Katherine. Search Atlas: Visualizing Divergent Search Results Across Geopolitical Borders. In: DIS ’21: Designing Interactive Systems Conference, 2021. Virtual Event USA: ACM, 2021. p. 1970–1983. Disponível em: https://dl.acm.org/doi/10.1145/3461778.3462032. Acesso em: 27 set. 2021.
↩